m = nn.Linear(10, 2)
inp = torch.randn(3, 10)
test_module_to_torchscript(m, inp, trace=True, script=True, serialize=True, verbose=True)output.shape: torch.Size([3, 2])
Tracing...
...Linear has been successfully traced 😃
TrueHelper functions used to build PyTorch timeseries models.
def test_module_to_torchscript(
m:Module, # The PyTorch module to be tested.
inputs:Tensor, # A tensor or tuple of tensors representing the inputs to the model.
trace:bool=True, # If `True`, attempts to trace the model. Defaults to `True`.
script:bool=True, # If `True`, attempts to script the model. Defaults to `True`.
serialize:bool=True, # If `True`, saves and loads the traced/scripted module to ensure it can be serialized. Defaults to `True`.
verbose:bool=True, # If `True`, prints detailed information about the tracing and scripting process. Defaults to `True`.
):
Tests if a PyTorch module can be correctly traced or scripted and serialized
m = nn.Linear(10, 2)
inp = torch.randn(3, 10)
test_module_to_torchscript(m, inp, trace=True, script=True, serialize=True, verbose=True)output.shape: torch.Size([3, 2])
Tracing...
...Linear has been successfully traced 😃
True
def init_lin_zero(
m
):
Call self as a function.
def SwishBeta(
):
Same as nn.Module, but no need for subclasses to call super().__init__
def SmeLU(
beta:float=2.0, # Beta value
)->None:
Smooth ReLU activation function based on https://arxiv.org/pdf/2202.06499.pdf
def Chomp1d(
chomp_size
):
Base class for all neural network modules.
Your models should also subclass this class.
Modules can also contain other Modules, allowing them to be nested in a tree structure. You can assign the submodules as regular attributes::
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))Submodules assigned in this way will be registered, and will also have their parameters converted when you call :meth:to, etc.
.. note:: As per the example above, an __init__() call to the parent class must be made before assignment on the child.
:ivar training: Boolean represents whether this module is in training or evaluation mode. :vartype training: bool
def SameConv1d(
ni, nf, ks:int=3, stride:int=1, dilation:int=1, kwargs:VAR_KEYWORD
):
Conv1d with padding=‘same’
def Pad1d(
padding, value:float=0.0
):
Pads the input tensor boundaries with a constant value.
For N-dimensional padding, use :func:torch.nn.functional.pad().
Args: padding (int, tuple): the size of the padding. If is int, uses the same padding in both boundaries. If a 2-tuple, uses (:math:\text{padding\_left}, :math:\text{padding\_right})
Shape: - Input: :math:(C, W_{in}) or :math:(N, C, W_{in}). - Output: :math:(C, W_{out}) or :math:(N, C, W_{out}), where
:math:`W_{out} = W_{in} + \text{padding\_left} + \text{padding\_right}`Examples::
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
>>> m = nn.ConstantPad1d(2, 3.5)
>>> input = torch.randn(1, 2, 4)
>>> input
tensor([[[-1.0491, -0.7152, -0.0749, 0.8530],
[-1.3287, 1.8966, 0.1466, -0.2771]]])
>>> m(input)
tensor([[[ 3.5000, 3.5000, -1.0491, -0.7152, -0.0749, 0.8530, 3.5000,
3.5000],
[ 3.5000, 3.5000, -1.3287, 1.8966, 0.1466, -0.2771, 3.5000,
3.5000]]])
>>> m = nn.ConstantPad1d(2, 3.5)
>>> input = torch.randn(1, 2, 3)
>>> input
tensor([[[ 1.6616, 1.4523, -1.1255],
[-3.6372, 0.1182, -1.8652]]])
>>> m(input)
tensor([[[ 3.5000, 3.5000, 1.6616, 1.4523, -1.1255, 3.5000, 3.5000],
[ 3.5000, 3.5000, -3.6372, 0.1182, -1.8652, 3.5000, 3.5000]]])
>>> # using different paddings for different sides
>>> m = nn.ConstantPad1d((3, 1), 3.5)
>>> m(input)
tensor([[[ 3.5000, 3.5000, 3.5000, 1.6616, 1.4523, -1.1255, 3.5000],
[ 3.5000, 3.5000, 3.5000, -3.6372, 0.1182, -1.8652, 3.5000]]])
def same_padding1d(
seq_len, ks, stride:int=1, dilation:int=1
):
Same padding formula as used in Tensorflow
def Conv2d(
ni, nf, kernel_size:NoneType=None, ks:NoneType=None, stride:int=1, padding:str='same', dilation:int=1,
init:str='auto', bias_std:float=0.01, kwargs:VAR_KEYWORD
):
conv1d layer with padding=‘same’, ‘valid’, or any integer (defaults to ‘same’)
def Conv2dSame(
ni, nf, ks:tuple=(3, 3), stride:tuple=(1, 1), dilation:tuple=(1, 1), kwargs:VAR_KEYWORD
):
Conv2d with padding=‘same’
def Pad2d(
padding, value:float=0.0
):
Pads the input tensor boundaries with a constant value.
For N-dimensional padding, use :func:torch.nn.functional.pad().
Args: padding (int, tuple): the size of the padding. If is int, uses the same padding in all boundaries. If a 4-tuple, uses (:math:\text{padding\_left}, :math:\text{padding\_right}, :math:\text{padding\_top}, :math:\text{padding\_bottom})
Shape: - Input: :math:(N, C, H_{in}, W_{in}) or :math:(C, H_{in}, W_{in}). - Output: :math:(N, C, H_{out}, W_{out}) or :math:(C, H_{out}, W_{out}), where
:math:`H_{out} = H_{in} + \text{padding\_top} + \text{padding\_bottom}`
:math:`W_{out} = W_{in} + \text{padding\_left} + \text{padding\_right}`Examples::
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
>>> m = nn.ConstantPad2d(2, 3.5)
>>> input = torch.randn(1, 2, 2)
>>> input
tensor([[[ 1.6585, 0.4320],
[-0.8701, -0.4649]]])
>>> m(input)
tensor([[[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 1.6585, 0.4320, 3.5000, 3.5000],
[ 3.5000, 3.5000, -0.8701, -0.4649, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000, 3.5000]]])
>>> # using different paddings for different sides
>>> m = nn.ConstantPad2d((3, 0, 2, 1), 3.5)
>>> m(input)
tensor([[[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000],
[ 3.5000, 3.5000, 3.5000, 1.6585, 0.4320],
[ 3.5000, 3.5000, 3.5000, -0.8701, -0.4649],
[ 3.5000, 3.5000, 3.5000, 3.5000, 3.5000]]])
def same_padding2d(
H, W, ks, stride:tuple=(1, 1), dilation:tuple=(1, 1)
):
Same padding formula as used in Tensorflow
bs = 2
c_in = 3
c_out = 5
h = 16
w = 20
t = torch.rand(bs, c_in, h, w)
test_eq(Conv2dSame(c_in, c_out, ks=3, stride=1, dilation=1, bias=False)(t).shape, (bs, c_out, h, w))
test_eq(Conv2dSame(c_in, c_out, ks=(3, 1), stride=1, dilation=1, bias=False)(t).shape, (bs, c_out, h, w))
test_eq(Conv2dSame(c_in, c_out, ks=3, stride=(1, 1), dilation=(2, 2), bias=False)(t).shape, (bs, c_out, h, w))
test_eq(Conv2dSame(c_in, c_out, ks=3, stride=(2, 2), dilation=(1, 1), bias=False)(t).shape, (bs, c_out, h//2, w//2))
test_eq(Conv2dSame(c_in, c_out, ks=3, stride=(2, 2), dilation=(2, 2), bias=False)(t).shape, (bs, c_out, h//2, w//2))
test_eq(Conv2d(c_in, c_out, ks=3, padding='same', stride=1, dilation=1, bias=False)(t).shape, (bs, c_out, h, w))
def CausalConv1d(
ni, nf, ks, stride:int=1, dilation:int=1, groups:int=1, bias:bool=True
):
Applies a 1D convolution over an input signal composed of several input planes.
In the simplest case, the output value of the layer with input size :math:(N, C_{\text{in}}, L) and output :math:(N, C_{\text{out}}, L_{\text{out}}) can be precisely described as:
.. math:: (N_i, C_{j}) = (C{j}) + {k = 0}^{C_{in} - 1} (C_{_j}, k) (N_i, k)
where :math:\star is the valid cross-correlation_ operator, :math:N is a batch size, :math:C denotes a number of channels, :math:L is a length of signal sequence.
This module supports :ref:TensorFloat32<tf32_on_ampere>.
On certain ROCm devices, when using float16 inputs this module will use :ref:different precision<fp16_on_mi200> for backward.
:attr:stride controls the stride for the cross-correlation, a single number or a one-element tuple.
:attr:padding controls the amount of padding applied to the input. It can be either a string {‘valid’, ‘same’} or a tuple of ints giving the amount of implicit padding applied on both sides.
:attr:dilation controls the spacing between the kernel points; also known as the à trous algorithm. It is harder to describe, but this link_ has a nice visualization of what :attr:dilation does.
:attr:groups controls the connections between inputs and outputs. :attr:in_channels and :attr:out_channels must both be divisible by :attr:groups. For example,
in_channels, each input channel is convolved with its own set of filters (of size :math:\frac{\text{out\_channels}}{\text{in\_channels}}).Note: When groups == in_channels and out_channels == K * in_channels, where K is a positive integer, this operation is also known as a “depthwise convolution”.
In other words, for an input of size :math:`(N, C_{in}, L_{in})`,
a depthwise convolution with a depthwise multiplier `K` can be performed with the arguments
:math:`(C_\text{in}=C_\text{in}, C_\text{out}=C_\text{in} \times \text{K}, ..., \text{groups}=C_\text{in})`.Note: In some circumstances when given tensors on a CUDA device and using CuDNN, this operator may select a nondeterministic algorithm to increase performance. If this is undesirable, you can try to make the operation deterministic (potentially at a performance cost) by setting torch.backends.cudnn.deterministic = True. See :doc:/notes/randomness for more information.
Note: padding='valid' is the same as no padding. padding='same' pads the input so the output has the shape as the input. However, this mode doesn’t support any stride values other than 1.
Note: This module supports complex data types i.e. complex32, complex64, complex128.
Args: in_channels (int): Number of channels in the input image out_channels (int): Number of channels produced by the convolution kernel_size (int or tuple): Size of the convolving kernel stride (int or tuple, optional): Stride of the convolution. Default: 1 padding (int, tuple or str, optional): Padding added to both sides of the input. Default: 0 dilation (int or tuple, optional): Spacing between kernel elements. Default: 1 groups (int, optional): Number of blocked connections from input channels to output channels. Default: 1 bias (bool, optional): If True, adds a learnable bias to the output. Default: True padding_mode (str, optional): 'zeros', 'reflect', 'replicate' or 'circular'. Default: 'zeros'
Shape: - Input: :math:(N, C_{in}, L_{in}) or :math:(C_{in}, L_{in}) - Output: :math:(N, C_{out}, L_{out}) or :math:(C_{out}, L_{out}), where
.. math::
L_{out} = \left\lfloor\frac{L_{in} + 2 \times \text{padding} - \text{dilation}
\times (\text{kernel\_size} - 1) - 1}{\text{stride}} + 1\right\rfloorAttributes: weight (Tensor): the learnable weights of the module of shape :math:(\text{out\_channels}, \frac{\text{in\_channels}}{\text{groups}}, \text{kernel\_size}). The values of these weights are sampled from :math:\mathcal{U}(-\sqrt{k}, \sqrt{k}) where :math:k = \frac{groups}{C_\text{in} * \text{kernel\_size}} bias (Tensor): the learnable bias of the module of shape (out_channels). If :attr:bias is True, then the values of these weights are sampled from :math:\mathcal{U}(-\sqrt{k}, \sqrt{k}) where :math:k = \frac{groups}{C_\text{in} * \text{kernel\_size}}
Examples::
>>> m = nn.Conv1d(16, 33, 3, stride=2)
>>> input = torch.randn(20, 16, 50)
>>> output = m(input).. _cross-correlation: https://en.wikipedia.org/wiki/Cross-correlation
.. _link: https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
def Conv1d(
ni, nf, kernel_size:NoneType=None, ks:NoneType=None, stride:int=1, padding:str='same', dilation:int=1,
init:str='auto', bias_std:float=0.01, kwargs:VAR_KEYWORD
):
conv1d layer with padding=‘same’, ‘causal’, ‘valid’, or any integer (defaults to ‘same’)
bs = 2
c_in = 3
c_out = 5
seq_len = 512
t = torch.rand(bs, c_in, seq_len)
dilation = 1
test_eq(CausalConv1d(c_in, c_out, ks=3, dilation=dilation)(t).shape, Conv1d(c_in, c_out, ks=3, padding="same", dilation=dilation)(t).shape)
dilation = 2
test_eq(CausalConv1d(c_in, c_out, ks=3, dilation=dilation)(t).shape, Conv1d(c_in, c_out, ks=3, padding="same", dilation=dilation)(t).shape)bs = 2
ni = 3
nf = 5
seq_len = 6
ks = 3
t = torch.rand(bs, c_in, seq_len)
test_eq(Conv1d(ni, nf, ks, padding=0)(t).shape, (bs, c_out, seq_len - (2 * (ks//2))))
test_eq(Conv1d(ni, nf, ks, padding='valid')(t).shape, (bs, c_out, seq_len - (2 * (ks//2))))
test_eq(Conv1d(ni, nf, ks, padding='same')(t).shape, (bs, c_out, seq_len))
test_eq(Conv1d(ni, nf, ks, padding='causal')(t).shape, (bs, c_out, seq_len))
test_error('use kernel_size or ks but not both simultaneously', Conv1d, ni, nf, kernel_size=3, ks=3)
test_error('you need to pass a ks', Conv1d, ni, nf)conv = Conv1d(ni, nf, ks, padding='same')
init_linear(conv, None, init='auto', bias_std=.01)
convConv1d(3, 5, kernel_size=(3,), stride=(1,), padding=(1,))conv = Conv1d(ni, nf, ks, padding='causal')
init_linear(conv, None, init='auto', bias_std=.01)
convCausalConv1d(3, 5, kernel_size=(3,), stride=(1,))conv = Conv1d(ni, nf, ks, padding='valid')
init_linear(conv, None, init='auto', bias_std=.01)
weight_norm(conv)
convConv1d(3, 5, kernel_size=(3,), stride=(1,))conv = Conv1d(ni, nf, ks, padding=0)
init_linear(conv, None, init='auto', bias_std=.01)
weight_norm(conv)
convConv1d(3, 5, kernel_size=(3,), stride=(1,))
def SeparableConv1d(
ni, nf, ks, stride:int=1, padding:str='same', dilation:int=1, bias:bool=True, bias_std:float=0.01
):
Same as nn.Module, but no need for subclasses to call super().__init__
bs = 64
c_in = 6
c_out = 5
seq_len = 512
t = torch.rand(bs, c_in, seq_len)
test_eq(SeparableConv1d(c_in, c_out, 3)(t).shape, (bs, c_out, seq_len))
def AddCoords1d(
):
Add coordinates to ease position identification without modifying mean and std
bs = 2
c_in = 3
c_out = 5
seq_len = 50
t = torch.rand(bs, c_in, seq_len)
t = (t - t.mean()) / t.std()
test_eq(AddCoords1d()(t).shape, (bs, c_in + 1, seq_len))
new_t = AddCoords1d()(t)
test_close(new_t.mean(),0, 1e-2)
test_close(new_t.std(), 1, 1e-2)
def ConvBlock(
ni, nf, kernel_size:NoneType=None, ks:int=3, stride:int=1, padding:str='same', bias:NoneType=None,
bias_std:float=0.01, norm:str='Batch', zero_norm:bool=False, bn_1st:bool=True, act:type=ReLU, act_kwargs:dict={},
init:str='auto', dropout:float=0.0, xtra:NoneType=None, coord:bool=False, separable:bool=False,
kwargs:VAR_KEYWORD
):
Create a sequence of conv1d (ni to nf), activation (if act_cls) and norm_type layers.
def ResBlock1dPlus(
expansion, ni, nf, coord:bool=False, stride:int=1, groups:int=1, reduction:NoneType=None, nh1:NoneType=None,
nh2:NoneType=None, dw:bool=False, g2:int=1, sa:bool=False, sym:bool=False, norm:str='Batch', zero_norm:bool=True,
act_cls:type=ReLU, ks:int=3, pool:function=AvgPool, pool_first:bool=True, kwargs:VAR_KEYWORD
):
Resnet block from ni to nh with stride
def SEModule1d(
ni, reduction:int=16, act:type=ReLU, act_kwargs:dict={}
):
Squeeze and excitation module for 1d
t = torch.rand(8, 32, 12)
test_eq(SEModule1d(t.shape[1], 16, act=nn.ReLU, act_kwargs={})(t).shape, t.shape)
def Norm(
nf, ndim:int=1, norm:str='Batch', zero_norm:bool=False, init:bool=True, kwargs:VAR_KEYWORD
):
Norm layer with nf features and ndim with auto init.
bs = 2
ni = 3
nf = 5
sl = 4
ks = 5
t = torch.rand(bs, ni, sl)
test_eq(ConvBlock(ni, nf, ks)(t).shape, (bs, nf, sl))
test_eq(ConvBlock(ni, nf, ks, padding='causal')(t).shape, (bs, nf, sl))
test_eq(ConvBlock(ni, nf, ks, coord=True)(t).shape, (bs, nf, sl))test_eq(BN1d(ni)(t).shape, (bs, ni, sl))
test_eq(BN1d(ni).weight.data.mean().item(), 1.)
test_eq(BN1d(ni, zero_norm=True).weight.data.mean().item(), 0.)test_eq(ConvBlock(ni, nf, ks, norm='batch', zero_norm=True)[1].weight.data.unique().item(), 0)
test_ne(ConvBlock(ni, nf, ks, norm='batch', zero_norm=False)[1].weight.data.unique().item(), 0)
test_eq(ConvBlock(ni, nf, ks, bias=False)[0].bias, None)
ConvBlock(ni, nf, ks, act=Swish, coord=True)ConvBlock(
(0): AddCoords1d()
(1): Conv1d(4, 5, kernel_size=(5,), stride=(1,), padding=(2,), bias=False)
(2): BatchNorm1d(5, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): SiLU()
)
def LinLnDrop(
n_in, n_out, ln:bool=True, p:float=0.0, act:NoneType=None, lin_first:bool=False
):
Module grouping LayerNorm1d, Dropout and Linear layers
LinLnDrop(2, 3, p=.5)LinLnDrop(
(0): LayerNorm((2,), eps=1e-05, elementwise_affine=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=2, out_features=3, bias=False)
)
def LambdaPlus(
func, args:VAR_POSITIONAL, kwargs:VAR_KEYWORD
):
Same as nn.Module, but no need for subclasses to call super().__init__
def ReZero(
module
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Clip(
min:NoneType=None, max:NoneType=None
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Clamp(
min:NoneType=None, max:NoneType=None
):
Same as nn.Module, but no need for subclasses to call super().__init__
def SoftMax(
dim:int=-1
):
SoftMax layer
def LastStep(
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Max(
dim:NoneType=None, keepdim:bool=False
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Reshape(
shape:VAR_POSITIONAL
):
Same as nn.Module, but no need for subclasses to call super().__init__
def View(
shape:VAR_POSITIONAL
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Transpose(
dims:VAR_POSITIONAL, contiguous:bool=True
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Permute(
dims:VAR_POSITIONAL
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Unfold(
dim, size, step:int=1
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Concat(
dim:int=1
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Add(
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Unsqueeze(
dim:int=-1
):
Same as nn.Module, but no need for subclasses to call super().__init__
def Squeeze(
dim:int=-1
):
Same as nn.Module, but no need for subclasses to call super().__init__
bs = 2
nf = 5
sl = 4
t = torch.rand(bs, nf, sl)
test_eq(Permute(0,2,1)(t).shape, (bs, sl, nf))
test_eq(Max(1)(t).shape, (bs, sl))
test_eq(Transpose(1,2)(t).shape, (bs, sl, nf))
test_eq(Transpose(1,2, contiguous=True)(t).shape, (bs, sl, nf))
test_eq(View(-1, 2, 10)(t).shape, (bs, 1, 2, 10))
test_eq(Reshape(-1, 2, 10)(t).shape, (bs, 1, 2, 10))
test_eq(Reshape()(t).shape, (2, 20))
test_eq(Reshape(-1)(t).shape, (40,))
test_eq(torch.jit.script(Reshape())(t).shape, (2, 20))
Transpose(1,2), Permute(0,2,1), View(-1, 2, 10), Transpose(1,2, contiguous=True), Reshape(-1, 2, 10), Noop(Transpose(dims=1, 2).contiguous(),
Permute(dims=0, 2, 1),
View(bs, -1, 2, 10),
Transpose(dims=1, 2).contiguous(),
Reshape(bs, -1, 2, 10),
Sequential())
def DropPath(
p:NoneType=None
):
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
It’s similar to Dropout but it drops individual connections instead of nodes. Original code in https://github.com/rwightman/pytorch-image-models (timm library)
t = torch.ones(100,2,3)
test_eq(DropPath(0.)(t), t)
assert DropPath(0.5)(t).max() >= 1
def Sharpen(
T:float=0.5
):
This is used to increase confidence in predictions - MixMatch paper
n_samples = 1000
n_classes = 3
t = (torch.rand(n_samples, n_classes) - .5) * 10
probas = F.softmax(t, -1)
sharpened_probas = Sharpen()(probas)
plt.plot(probas.flatten().sort().values, color='r')
plt.plot(sharpened_probas.flatten().sort().values, color='b')
plt.show()
test_gt(sharpened_probas[n_samples//2:].max(-1).values.sum().item(), probas[n_samples//2:].max(-1).values.sum().item())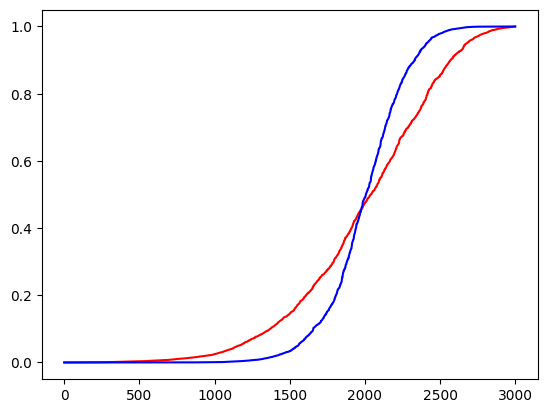
def Sequential(
args:VAR_POSITIONAL
):
Class that allows you to pass one or multiple inputs
def TimeDistributed(
module, batch_first:bool=False
):
Base class for all neural network modules.
Your models should also subclass this class.
Modules can also contain other Modules, allowing them to be nested in a tree structure. You can assign the submodules as regular attributes::
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))Submodules assigned in this way will be registered, and will also have their parameters converted when you call :meth:to, etc.
.. note:: As per the example above, an __init__() call to the parent class must be made before assignment on the child.
:ivar training: Boolean represents whether this module is in training or evaluation mode. :vartype training: bool
def get_calibrator(
calibrator:NoneType=None, n_classes:int=1, kwargs:VAR_KEYWORD
):
Call self as a function.
def Matrix_Scale(
n_classes:int=1, dirichlet:bool=False
):
Used to perform Matrix Scaling (dirichlet=False) or Dirichlet calibration (dirichlet=True)
def Vector_Scale(
n_classes:int=1, dirichlet:bool=False
):
Used to perform Vector Scaling (dirichlet=False) or Diagonal Dirichlet calibration (dirichlet=True)
def Temp_Scale(
temp:float=1.0, dirichlet:bool=False
):
Used to perform Temperature Scaling (dirichlet=False) or Single-parameter Dirichlet calibration (dirichlet=True)
bs = 2
c_out = 3
t = torch.rand(bs, c_out)
for calibrator, cal_name in zip(['temp', 'vector', 'matrix'], ['Temp_Scale', 'Vector_Scale', 'Matrix_Scale']):
cal = get_calibrator(calibrator, n_classes=c_out)
# print(calibrator)
# print(cal.weight, cal.bias, '\n')
test_eq(cal(t), t)
test_eq(cal.__class__.__name__, cal_name)
for calibrator, cal_name in zip(['dtemp', 'dvector', 'dmatrix'], ['Temp_Scale', 'Vector_Scale', 'Matrix_Scale']):
cal = get_calibrator(calibrator, n_classes=c_out)
# print(calibrator)
# print(cal.weight, cal.bias, '\n')
test_eq(cal(t), F.log_softmax(t, dim=1))
test_eq(cal.__class__.__name__, cal_name)bs = 2
c_out = 3
t = torch.rand(bs, c_out)
test_eq(Temp_Scale()(t).shape, t.shape)
test_eq(Vector_Scale(c_out)(t).shape, t.shape)
test_eq(Matrix_Scale(c_out)(t).shape, t.shape)
test_eq(Temp_Scale(dirichlet=True)(t).shape, t.shape)
test_eq(Vector_Scale(c_out, dirichlet=True)(t).shape, t.shape)
test_eq(Matrix_Scale(c_out, dirichlet=True)(t).shape, t.shape)
test_eq(Temp_Scale()(t), t)
test_eq(Vector_Scale(c_out)(t), t)
test_eq(Matrix_Scale(c_out)(t), t)bs = 2
c_out = 5
t = torch.rand(bs, c_out)
test_eq(Vector_Scale(c_out)(t), t)
test_eq(Vector_Scale(c_out).weight.data, torch.ones(c_out))
test_eq(Vector_Scale(c_out).weight.requires_grad, True)
test_eq(type(Vector_Scale(c_out).weight), torch.nn.parameter.Parameter)bs = 2
c_out = 3
weight = 2
bias = 1
t = torch.rand(bs, c_out)
test_eq(Matrix_Scale(c_out)(t).shape, t.shape)
test_eq(Matrix_Scale(c_out).weight.requires_grad, True)
test_eq(type(Matrix_Scale(c_out).weight), torch.nn.parameter.Parameter)
def LogitAdjustmentLayer(
class_priors
):
Logit Adjustment for imbalanced datasets
bs, n_classes = 16, 3
class_priors = torch.rand(n_classes)
logits = torch.randn(bs, n_classes) * 2
test_eq(LogitAdjLayer(class_priors)(logits), logits + class_priors)
def MaxPPVPool1d(
):
Drop-in replacement for AdaptiveConcatPool1d - multiplies nf by 2
def PPAuc(
dim:int=-1
):
Same as nn.Module, but no need for subclasses to call super().__init__
def PPV(
dim:int=-1
):
Same as nn.Module, but no need for subclasses to call super().__init__
bs = 2
nf = 5
sl = 4
t = torch.rand(bs, nf, sl)
test_eq(MaxPPVPool1d()(t).shape, (bs, nf*2, 1))
test_eq(MaxPPVPool1d()(t).shape, AdaptiveConcatPool1d(1)(t).shape)
def AdaptiveWeightedAvgPool1d(
n_in, seq_len, mult:int=2, n_layers:int=2, ln:bool=False, dropout:float=0.5, act:ReLU=ReLU(),
zero_init:bool=True
):
Global Pooling layer that performs a weighted average along the temporal axis
It can be considered as a channel-wise form of local temporal attention. Inspired by the paper: Hyun, J., Seong, H., & Kim, E. (2019). Universal Pooling–A New Pooling Method for Convolutional Neural Networks. arXiv preprint arXiv:1907.11440.
def GAWP1d(
n_in, seq_len, n_layers:int=2, ln:bool=False, dropout:float=0.5, act:ReLU=ReLU(), zero_init:bool=False
):
Global AdaptiveWeightedAvgPool1d + Flatten
def GACP1d(
output_size:int=1
):
Global AdaptiveConcatPool + Flatten
def GAP1d(
output_size:int=1
):
Global Adaptive Pooling + Flatten
def gwa_pool_head(
n_in, c_out, seq_len, bn:bool=True, fc_dropout:float=0.0
):
Call self as a function.
def GlobalWeightedAveragePool1d(
n_in, seq_len
):
Global Weighted Average Pooling layer
Inspired by Building Efficient CNN Architecture for Offline Handwritten Chinese Character Recognition https://arxiv.org/pdf/1804.01259.pdf
t = torch.randn(16, 64, 50)
head = gwa_pool_head(64, 5, 50)
test_eq(head(t).shape, (16, 5))
def attentional_pool_head(
n_in, c_out, seq_len:NoneType=None, bn:bool=True, kwargs:VAR_KEYWORD
):
Call self as a function.
def GAttP1d(
n_in, c_out, bn:bool=False
):
A sequential container.
Modules will be added to it in the order they are passed in the constructor. Alternatively, an OrderedDict of modules can be passed in. The forward() method of [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) accepts any input and forwards it to the first module it contains. It then “chains” outputs to inputs sequentially for each subsequent module, finally returning the output of the last module.
The value a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) provides over manually calling a sequence of modules is that it allows treating the whole container as a single module, such that performing a transformation on the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) applies to each of the modules it stores (which are each a registered submodule of the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential)).
What’s the difference between a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) and a :class:torch.nn.ModuleList? A ModuleList is exactly what it sounds like–a list for storing Module s! On the other hand, the layers in a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) are connected in a cascading way.
Example::
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(
OrderedDict(
[
("conv1", nn.Conv2d(1, 20, 5)),
("relu1", nn.ReLU()),
("conv2", nn.Conv2d(20, 64, 5)),
("relu2", nn.ReLU()),
]
)
)
def AttentionalPool1d(
n_in, c_out, bn:bool=False
):
Global Adaptive Pooling layer inspired by Attentional Pooling for Action Recognition https://arxiv.org/abs/1711.01467
bs, c_in, seq_len = 16, 1, 50
c_out = 3
t = torch.rand(bs, c_in, seq_len)
test_eq(GAP1d()(t).shape, (bs, c_in))
test_eq(GACP1d()(t).shape, (bs, c_in*2))
bs, c_in, seq_len = 16, 4, 50
t = torch.rand(bs, c_in, seq_len)
test_eq(GAP1d()(t).shape, (bs, c_in))
test_eq(GACP1d()(t).shape, (bs, c_in*2))
test_eq(GAWP1d(c_in, seq_len, n_layers=2, ln=False, dropout=0.5, act=nn.ReLU(), zero_init=False)(t).shape, (bs, c_in))
test_eq(GAWP1d(c_in, seq_len, n_layers=2, ln=False, dropout=0.5, act=nn.ReLU(), zero_init=False)(t).shape, (bs, c_in))
test_eq(GAWP1d(c_in, seq_len, n_layers=1, ln=False, dropout=0.5, zero_init=False)(t).shape, (bs, c_in))
test_eq(GAWP1d(c_in, seq_len, n_layers=1, ln=False, dropout=0.5, zero_init=True)(t).shape, (bs, c_in))
test_eq(AttentionalPool1d(c_in, c_out)(t).shape, (bs, c_out, 1))bs, c_in, seq_len = 16, 128, 50
c_out = 14
t = torch.rand(bs, c_in, seq_len)
attp = attentional_pool_head(c_in, c_out)
test_eq(attp(t).shape, (bs, c_out))
def PoolingLayer(
method:str='cls', seq_len:NoneType=None, token:bool=True, seq_last:bool=True
):
Same as nn.Module, but no need for subclasses to call super().__init__
t = torch.arange(24).reshape(2, 3, 4).float()
test_eq(PoolingLayer('cls', token=True, seq_last=True)(t), tensor([[ 0., 4., 8.], [12., 16., 20.]]))
test_eq(PoolingLayer('max', token=True, seq_last=True)(t), tensor([[ 3., 7., 11.], [15., 19., 23.]]))
test_close(PoolingLayer('mean', token=True, seq_last=True)(t), tensor([[ 2., 6., 10.], [14., 18., 22.]]))
test_close(PoolingLayer('max-mean', token=True, seq_last=True)(t), tensor([[ 3., 7., 11., 2., 6., 10.],
[15., 19., 23., 14., 18., 22.]]))
test_close(PoolingLayer('flatten', token=True, seq_last=True)(t), tensor([[ 1., 2., 3., 5., 6., 7., 9., 10., 11.],
[13., 14., 15., 17., 18., 19., 21., 22., 23.]]))
test_eq(PoolingLayer('linear', seq_len=4, token=True, seq_last=True)(t).shape, (2, 3))
test_eq(PoolingLayer('max', token=False, seq_last=True)(t), tensor([[ 3., 7., 11.], [15., 19., 23.]]))
test_close(PoolingLayer('mean', token=False, seq_last=True)(t), tensor([[ 1.5000, 5.5000, 9.5000],
[13.5000, 17.5000, 21.5000]]))
test_close(PoolingLayer('max-mean', token=False, seq_last=True)(t), tensor([[ 3., 7., 11., 1.5000, 5.5000, 9.5000],
[15., 19., 23., 13.5000, 17.5000, 21.5000]]))
test_close(PoolingLayer('flatten', token=False, seq_last=True)(t), tensor([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23.]]))
test_eq(PoolingLayer('linear', seq_len=4, token=False, seq_last=True)(t).shape, (2, 3))t = torch.arange(24).reshape(2, 3, 4).swapaxes(1,2).float()
test_eq(PoolingLayer('cls', token=True, seq_last=False)(t), tensor([[ 0., 4., 8.], [12., 16., 20.]]))
test_eq(PoolingLayer('max', token=True, seq_last=False)(t), tensor([[ 3., 7., 11.], [15., 19., 23.]]))
test_close(PoolingLayer('mean', token=True, seq_last=False)(t), tensor([[ 2., 6., 10.], [14., 18., 22.]]))
test_close(PoolingLayer('max-mean', token=True, seq_last=False)(t), tensor([[ 3., 7., 11., 2., 6., 10.],
[15., 19., 23., 14., 18., 22.]]))
test_close(PoolingLayer('flatten', token=True, seq_last=False)(t), tensor([[ 1., 5., 9., 2., 6., 10., 3., 7., 11.],
[13., 17., 21., 14., 18., 22., 15., 19., 23.]]))
t = torch.arange(24).reshape(2, 3, 4).swapaxes(1,2).float()
test_eq(PoolingLayer('conv1d', seq_len=4, token=False, seq_last=False)(t).shape, (2, 3))
test_eq(PoolingLayer('max', token=False, seq_last=False)(t), tensor([[ 3., 7., 11.], [15., 19., 23.]]))
test_close(PoolingLayer('mean', token=False, seq_last=False)(t), tensor([[ 1.5000, 5.5000, 9.5000],
[13.5000, 17.5000, 21.5000]]))
test_close(PoolingLayer('max-mean', token=False, seq_last=False)(t), tensor([[ 3., 7., 11., 1.5000, 5.5000, 9.5000],
[15., 19., 23., 13.5000, 17.5000, 21.5000]]))
test_close(PoolingLayer('flatten', token=False, seq_last=False)(t), tensor([[ 0., 4., 8., 1., 5., 9., 2., 6., 10., 3., 7., 11.],
[12., 16., 20., 13., 17., 21., 14., 18., 22., 15., 19., 23.]]))
test_eq(PoolingLayer('conv1d', seq_len=4, token=False, seq_last=False)(t).shape, (2, 3))
def ReGLU(
):
Same as nn.Module, but no need for subclasses to call super().__init__
def GEGLU(
):
Same as nn.Module, but no need for subclasses to call super().__init__
def get_act_fn(
act, act_kwargs:VAR_KEYWORD
):
Call self as a function.
test_eq(get_act_fn(nn.ReLU).__repr__(), "ReLU()")
test_eq(get_act_fn(nn.ReLU()).__repr__(), "ReLU()")
test_eq(get_act_fn(nn.LeakyReLU, negative_slope=0.05).__repr__(), "LeakyReLU(negative_slope=0.05)")
test_eq(get_act_fn('reglu').__repr__(), "ReGLU()")
test_eq(get_act_fn('leakyrelu', negative_slope=0.05).__repr__(), "LeakyReLU(negative_slope=0.05)")
def RevIN(
c_in:int, # #features (aka variables or channels)
affine:bool=True, # flag to incidate if RevIN has learnable weight and bias
subtract_last:bool=False, dim:int=2, # int or tuple of dimensions used to calculate mean and std
eps:float=1e-05, # epsilon - parameter added for numerical stability
):
Reversible Instance Normalization layer adapted from
Kim, T., Kim, J., Tae, Y., Park, C., Choi, J. H., & Choo, J. (2021, September). Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations. Original code: https://github.com/ts-kim/RevIN
def RevIN(
c_in:int, # #features (aka variables or channels)
affine:bool=True, # flag to incidate if RevIN has learnable weight and bias
subtract_last:bool=False, dim:int=2, # int or tuple of dimensions used to calculate mean and std
eps:float=1e-05, # epsilon - parameter added for numerical stability
):
Reversible Instance Normalization layer adapted from
Kim, T., Kim, J., Tae, Y., Park, C., Choi, J. H., & Choo, J. (2021, September). Reversible instance normalization for accurate time-series forecasting against distribution shift. In International Conference on Learning Representations. Original code: https://github.com/ts-kim/RevIN
t = ((torch.rand(16, 5, 100) - .25) * torch.Tensor([.01, .1, 1, 10, 100]).reshape(1, -1, 1)).cumsum(-1)
t_clone = t.clone()
l = RevIN(5)
t_norm = l(t, torch.tensor(True))
t_denorm = l(t_norm, torch.tensor(False))
test_close(t_clone, t_denorm, eps=1e-3)model = RevIN(5, affine=True)
try:
scripted_model = torch.jit.script(model)
file_path = f"test_scripted_model.pt"
torch.jit.save(scripted_model, file_path)
scripted_model = torch.jit.load(file_path)
inp = ((torch.rand(16, 5, 100) - .25) * torch.Tensor([.01, .1, 1, 10, 100]).reshape(1, -1, 1)).cumsum(-1)
normed_output = model(inp, torch.tensor(True))
demormed_output = model(normed_output, torch.tensor(False))
scripted_normed_output = scripted_model(inp, torch.tensor(True))
scripted_denormed_output = scripted_model(scripted_normed_output, torch.tensor(False))
test_close(normed_output, scripted_normed_output)
test_close(demormed_output, scripted_denormed_output)
os.remove(file_path)
del scripted_model
gc.collect()
print('scripting ok')
except Exception as e:
print(f'scripting failed: {e}')scripting ok
def create_pool_head(
n_in, c_out, seq_len:NoneType=None, concat_pool:bool=False, fc_dropout:float=0.0, bn:bool=False,
y_range:NoneType=None, kwargs:VAR_KEYWORD
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_pool_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
test_eq(create_pool_head(nf, c_out, seq_len, concat_pool=True, fc_dropout=0.5)(t).shape, (bs, c_out))
create_pool_head(nf, c_out, seq_len, concat_pool=True, bn=True, fc_dropout=.5)Sequential(
(0): GACP1d(
(gacp): AdaptiveConcatPool1d(
(ap): AdaptiveAvgPool1d(output_size=1)
(mp): AdaptiveMaxPool1d(output_size=1)
)
(flatten): Reshape(bs)
)
(1): LinBnDrop(
(0): BatchNorm1d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=24, out_features=2, bias=False)
)
)
def max_pool_head(
n_in, c_out, seq_len, fc_dropout:float=0.0, bn:bool=False, y_range:NoneType=None, kwargs:VAR_KEYWORD
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(max_pool_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
def create_pool_plus_head(
args:VAR_POSITIONAL, lin_ftrs:NoneType=None, fc_dropout:float=0.0, concat_pool:bool=True, bn_final:bool=False,
lin_first:bool=False, y_range:NoneType=None
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_pool_plus_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
test_eq(create_pool_plus_head(nf, c_out, concat_pool=True, fc_dropout=0.5)(t).shape, (bs, c_out))
create_pool_plus_head(nf, c_out, seq_len, fc_dropout=0.5)Sequential(
(0): AdaptiveConcatPool1d(
(ap): AdaptiveAvgPool1d(output_size=1)
(mp): AdaptiveMaxPool1d(output_size=1)
)
(1): Reshape(bs)
(2): BatchNorm1d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Dropout(p=0.25, inplace=False)
(4): Linear(in_features=24, out_features=512, bias=False)
(5): ReLU(inplace=True)
(6): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): Dropout(p=0.5, inplace=False)
(8): Linear(in_features=512, out_features=2, bias=False)
)
def create_conv_head(
args:VAR_POSITIONAL, adaptive_size:NoneType=None, y_range:NoneType=None
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_conv_head(nf, c_out, seq_len)(t).shape, (bs, c_out))
test_eq(create_conv_head(nf, c_out, adaptive_size=50)(t).shape, (bs, c_out))
create_conv_head(nf, c_out, 50)Sequential(
(0): ConvBlock(
(0): Conv1d(12, 6, kernel_size=(1,), stride=(1,), bias=False)
(1): BatchNorm1d(6, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): ConvBlock(
(0): Conv1d(6, 3, kernel_size=(1,), stride=(1,), bias=False)
(1): BatchNorm1d(3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(2): ConvBlock(
(0): Conv1d(3, 2, kernel_size=(1,), stride=(1,), bias=False)
(1): BatchNorm1d(2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(3): GAP1d(
(gap): AdaptiveAvgPool1d(output_size=1)
(flatten): Reshape(bs)
)
)
def create_mlp_head(
nf, c_out, seq_len:NoneType=None, flatten:bool=True, fc_dropout:float=0.0, bn:bool=False, lin_first:bool=False,
y_range:NoneType=None
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_mlp_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
t = torch.rand(bs, nf, seq_len)
create_mlp_head(nf, c_out, seq_len, bn=True, fc_dropout=.5)Sequential(
(0): Reshape(bs)
(1): LinBnDrop(
(0): BatchNorm1d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=240, out_features=2, bias=False)
)
)
def create_fc_head(
nf, c_out, seq_len:NoneType=None, flatten:bool=True, lin_ftrs:NoneType=None, y_range:NoneType=None,
fc_dropout:float=0.0, bn:bool=False, bn_final:bool=False, act:ReLU=ReLU(inplace=True)
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_fc_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
create_mlp_head(nf, c_out, seq_len, bn=True, fc_dropout=.5)Sequential(
(0): Reshape(bs)
(1): LinBnDrop(
(0): BatchNorm1d(240, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=240, out_features=2, bias=False)
)
)
def create_rnn_head(
args:VAR_POSITIONAL, fc_dropout:float=0.0, bn:bool=False, y_range:NoneType=None
):
Call self as a function.
bs = 16
nf = 12
c_out = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
test_eq(create_rnn_head(nf, c_out, seq_len, fc_dropout=0.5)(t).shape, (bs, c_out))
create_rnn_head(nf, c_out, seq_len, bn=True, fc_dropout=.5)Sequential(
(0): LastStep()
(1): LinBnDrop(
(0): BatchNorm1d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=12, out_features=2, bias=False)
)
)
def imputation_head(
c_in, c_out, seq_len:NoneType=None, ks:int=1, y_range:NoneType=None, fc_dropout:float=0.0
):
Call self as a function.
bs = 16
nf = 12
ni = 2
seq_len = 20
t = torch.rand(bs, nf, seq_len)
head = imputation_head(nf, ni, seq_len=None, ks=1, y_range=None, fc_dropout=0.)
test_eq(head(t).shape, (bs, ni, seq_len))
head = imputation_head(nf, ni, seq_len=None, ks=1, y_range=(.3,.7), fc_dropout=0.)
test_ge(head(t).min(), .3)
test_le(head(t).max(), .7)
y_range = (tensor([0.1000, 0.1000, 0.1000, 0.1000, 0.2000, 0.2000, 0.2000, 0.2000, 0.3000,
0.3000, 0.3000, 0.3000]),
tensor([0.6000, 0.6000, 0.6000, 0.6000, 0.7000, 0.7000, 0.7000, 0.7000, 0.8000,
0.8000, 0.8000, 0.8000]))
test_ge(head(t).min(), .1)
test_le(head(t).max(), .9)
head = imputation_head(nf, ni, seq_len=None, ks=1, y_range=y_range, fc_dropout=0.)
headSequential(
(0): Dropout(p=0.0, inplace=False)
(1): Conv1d(12, 2, kernel_size=(1,), stride=(1,))
(2): fastai.layers.SigmoidRange(low=tensor([0.1000, 0.1000, 0.1000, 0.1000, 0.2000, 0.2000, 0.2000, 0.2000, 0.3000,
0.3000, 0.3000, 0.3000]), high=tensor([0.6000, 0.6000, 0.6000, 0.6000, 0.7000, 0.7000, 0.7000, 0.7000, 0.8000,
0.8000, 0.8000, 0.8000]))
)
def create_conv_lin_nd_head(
n_in, n_out, seq_len, d, conv_first:bool=True, conv_bn:bool=False, lin_bn:bool=False, fc_dropout:float=0.0,
kwargs:VAR_KEYWORD
):
Module to create a nd output head
bs = 16
nf = 32
c = 5
seq_len = 10
d = 2
targ = torch.randint(0, c, (bs,d))
t = torch.randn(bs, nf, seq_len)
head = conv_lin_nd_head(nf, c, seq_len, d, conv_first=True, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, (bs, d, c))
loss = CrossEntropyLossFlat()(inp, targ)
loss, head(TensorBase(1.7252, grad_fn=<AliasBackward0>),
create_conv_lin_nd_head(
(0): Conv1d(32, 5, kernel_size=(1,), stride=(1,))
(1): Dropout(p=0.5, inplace=False)
(2): Linear(in_features=10, out_features=2, bias=True)
(3): Transpose(dims=-1, -2).contiguous()
(4): Reshape(bs, 2, 5)
))bs = 16
nf = 32
c = 5
seq_len = 10
d = [2, 8]
targ = torch.randint(0, c, [bs]+d)
t = torch.randn(bs, nf, seq_len)
head = conv_lin_nd_head(nf, c, seq_len, d, conv_first=False, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, [bs]+d+[c])
loss = CrossEntropyLossFlat()(inp, targ)
loss, head(TensorBase(1.6647, grad_fn=<AliasBackward0>),
create_conv_lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=10, out_features=16, bias=True)
(2): Conv1d(32, 5, kernel_size=(1,), stride=(1,))
(3): Transpose(dims=-1, -2).contiguous()
(4): Reshape(bs, 2, 8, 5)
))bs = 16
nf = 32
c = 1
seq_len = 10
d = 2
targ = torch.rand(bs, d)
t = torch.randn(bs, nf, seq_len)
head = conv_lin_nd_head(nf, c, seq_len, d, conv_first=False, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, (bs, d))
loss = L1LossFlat()(inp, targ)
loss, head(TensorBase(0.7063, grad_fn=<AliasBackward0>),
create_conv_lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=10, out_features=2, bias=True)
(2): Conv1d(32, 1, kernel_size=(1,), stride=(1,))
(3): Transpose(dims=-1, -2).contiguous()
(4): Reshape(bs, 2)
))bs = 16
nf = 32
c = 1
seq_len = 10
d = [2,3]
targ = torch.rand(bs, *d)
t = torch.randn(bs, nf, seq_len)
head = conv_lin_nd_head(nf, c, seq_len, d, conv_first=False, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, [bs]+d)
loss = L1LossFlat()(inp, targ)
loss, head(TensorBase(0.6203, grad_fn=<AliasBackward0>),
create_conv_lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=10, out_features=6, bias=True)
(2): Conv1d(32, 1, kernel_size=(1,), stride=(1,))
(3): Transpose(dims=-1, -2).contiguous()
(4): Reshape(bs, 2, 3)
))
def lin_nd_head(
n_in, n_out, seq_len:NoneType=None, d:NoneType=None, flatten:bool=False, use_bn:bool=False, fc_dropout:float=0.0
):
Module to create a nd output head with linear layers
bs = 16
nf = 32
seq_len = 50
x = torch.normal(0, 1, (bs, nf, seq_len))
for use_bn in [False, True]:
for fc_dropout in [0, 0.2]:
for flatten in [False, True]:
for c in [1, 3]:
for d in [None, (50,), (50,10), (30,5), (50,2,3), (30,2,3)]:
for q_len in [1, seq_len]:
head = lin_nd_head(nf, c, q_len, d, flatten=flatten, use_bn=use_bn, fc_dropout=fc_dropout)
test_eq(head(x).shape, (bs, ) + (d if d is not None else ()) + ((c,) if c != 1 else ()))bs = 16
nf = 32
c = 5
seq_len = 10
d = 2
targ = torch.randint(0, c, (bs,d))
t = torch.randn(bs, nf, seq_len)
head = lin_nd_head(nf, c, seq_len, d, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, (bs, d, c))
loss = CrossEntropyLossFlat()(inp, targ)
loss, head(TensorBase(1.7711, grad_fn=<AliasBackward0>),
lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Reshape(bs)
(2): Linear(in_features=320, out_features=10, bias=True)
(3): Reshape(bs, 2, 5)
))bs = 16
nf = 32
c = 5
seq_len = 10
d = [2, 8]
targ = torch.randint(0, c, [bs]+d)
t = torch.randn(bs, nf, seq_len)
head = lin_nd_head(nf, c, seq_len, d, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, [bs]+d+[c])
loss = CrossEntropyLossFlat()(inp, targ)
loss, head(TensorBase(1.8884, grad_fn=<AliasBackward0>),
lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Reshape(bs)
(2): Linear(in_features=320, out_features=80, bias=True)
(3): Reshape(bs, 2, 8, 5)
))bs = 16
nf = 32
c = 1
seq_len = 10
d = 2
targ = torch.rand(bs, d)
t = torch.randn(bs, nf, seq_len)
head = lin_nd_head(nf, c, seq_len, d, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, (bs, d))
loss = L1LossFlat()(inp, targ)
loss, head(TensorBase(0.7737, grad_fn=<AliasBackward0>),
lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Reshape(bs)
(2): Linear(in_features=320, out_features=2, bias=True)
(3): Reshape(bs, 2)
))bs = 16
nf = 32
c = 1
seq_len = 10
d = [2,3]
targ = torch.rand(bs, *d)
t = torch.randn(bs, nf, seq_len)
head = lin_nd_head(nf, c, seq_len, d, fc_dropout=.5)
inp = head(t)
test_eq(inp.shape, [bs]+d)
loss = L1LossFlat()(inp, targ)
loss, head(TensorBase(0.8873, grad_fn=<AliasBackward0>),
lin_nd_head(
(0): Dropout(p=0.5, inplace=False)
(1): Reshape(bs)
(2): Linear(in_features=320, out_features=6, bias=True)
(3): Reshape(bs, 2, 3)
))
def rocket_nd_head(
n_in, n_out, seq_len:NoneType=None, d:NoneType=None, use_bn:bool=False, fc_dropout:float=0.0,
zero_init:bool=True
):
Module to create a nd output head with linear layers for the rocket family of models
bs = 16
nf = 99
seq_len = 1
x = torch.normal(0, 1, (bs, nf, seq_len))
for use_bn in [False, True]:
for fc_dropout in [0, 0.2]:
for c in [1, 3]:
for d in [None, (50,), (50,10), (30,5), (50,2,3), (30,2,3)]:
head = rocket_nd_head(nf, c, 1, d, use_bn=use_bn, fc_dropout=fc_dropout)
test_eq(head(x).shape, (bs, ) + (d if d is not None else ()) + ((c,) if c != 1 else ()))
def xresnet1d_nd_head(
n_in, n_out, seq_len:NoneType=None, d:NoneType=None, use_bn:bool=False, fc_dropout:float=0.0,
zero_init:bool=True
):
Module to create a nd output head with linear layers for the xresnet family of models
bs = 16
nf = 99
seq_len = 2
x = torch.normal(0, 1, (bs, nf, seq_len))
for use_bn in [False, True]:
for fc_dropout in [0, 0.2]:
for c in [1, 3]:
for d in [None, (50,), (50,10), (30,5), (50,2,3), (30,2,3)]:
head = xresnet1d_nd_head(nf, c, 1, d, use_bn=use_bn, fc_dropout=fc_dropout)
test_eq(head(x).shape, (bs, ) + (d if d is not None else ()) + ((c,) if c != 1 else ()))
def create_conv_3d_head(
n_in, n_out, seq_len, d, use_bn:bool=False, kwargs:VAR_KEYWORD
):
Module to create a nd output head with a convolutional layer
bs = 16
nf = 32
c = 5
seq_len = 10
d = 10
targ = torch.randint(0, c, (bs,d))
t = torch.randn(bs, nf, seq_len)
head = conv_3d_head(nf, c, seq_len, d)
inp = head(t)
test_eq(inp.shape, (bs, d, c))
loss = CrossEntropyLossFlat()(inp, targ)
loss, head(TensorBase(1.8352, grad_fn=<AliasBackward0>),
create_conv_3d_head(
(0): ConvBlock(
(0): Conv1d(32, 5, kernel_size=(1,), stride=(1,))
)
(1): Transpose(dims=-1, -2).contiguous()
))bs = 16
nf = 32
c = 1
seq_len = 10
d = 10
targ = torch.rand(bs, d)
t = torch.randn(bs, nf, seq_len)
head = conv_3d_head(nf, c, seq_len, d)
inp = head(t)
test_eq(inp.shape, (bs, d))
loss = L1LossFlat()(inp, targ)
loss, head(TensorBase(0.6711, grad_fn=<AliasBackward0>),
create_conv_3d_head(
(0): ConvBlock(
(0): Conv1d(32, 1, kernel_size=(1,), stride=(1,))
)
(1): Transpose(dims=-1, -2).contiguous()
(2): Squeeze(dim=-1)
))
def universal_pool_head(
n_in, c_out, seq_len, mult:int=2, pool_n_layers:int=2, pool_ln:bool=True, pool_dropout:float=0.5,
pool_act:ReLU=ReLU(), zero_init:bool=True, bn:bool=True, fc_dropout:float=0.0
):
Call self as a function.
bs, c_in, seq_len = 16, 128, 50
c_out = 14
t = torch.rand(bs, c_in, seq_len)
uph = universal_pool_head(c_in, c_out, seq_len)
test_eq(uph(t).shape, (bs, c_out))
uph = universal_pool_head(c_in, c_out, seq_len, 2)
test_eq(uph(t).shape, (bs, c_out))bs, c_in, seq_len = 16, 128, 50
c_out = 14
d = 5
t = torch.rand(bs, c_in, seq_len)
for head in heads:
print(head.__name__)
if head.__name__ == "create_conv_3d_head":
h = head(c_in, c_out, seq_len, seq_len)
test_eq(h(t).shape, (bs, seq_len, c_out))
elif 'nd' in head.__name__:
h = head(c_in, c_out, seq_len, d)
test_eq(h(t).shape, (bs, d, c_out))
else:
h = head(c_in, c_out, seq_len)
test_eq(h(t).shape, (bs, c_out))create_mlp_head
create_fc_head
average_pool_head
max_pool_head
concat_pool_head
create_pool_plus_head
create_conv_head
create_rnn_head
create_conv_lin_nd_head
lin_nd_head
create_conv_3d_head
attentional_pool_head
universal_pool_head
gwa_pool_head
def SqueezeExciteBlock(
ni, reduction:int=16
):
Same as nn.Module, but no need for subclasses to call super().__init__
bs = 2
ni = 32
sl = 4
t = torch.rand(bs, ni, sl)
test_eq(SqueezeExciteBlock(ni)(t).shape, (bs, ni, sl))
def GaussianNoise(
sigma:float=0.1, is_relative_detach:bool=True
):
Gaussian noise regularizer.
Args: sigma (float, optional): relative standard deviation used to generate the noise. Relative means that it will be multiplied by the magnitude of the value your are adding the noise to. This means that sigma can be the same regardless of the scale of the vector. is_relative_detach (bool, optional): whether to detach the variable before computing the scale of the noise. If False then the scale of the noise won’t be seen as a constant but something to optimize: this will bias the network to generate vectors with smaller values.
t = torch.ones(2,3,4)
test_ne(GaussianNoise()(t), t)
test_eq(GaussianNoise()(t).shape, t.shape)
t = torch.ones(2,3)
test_ne(GaussianNoise()(t), t)
test_eq(GaussianNoise()(t).shape, t.shape)
t = torch.ones(2)
test_ne(GaussianNoise()(t), t)
test_eq(GaussianNoise()(t).shape, t.shape)
def TokenLayer(
token:bool=True
):
Same as nn.Module, but no need for subclasses to call super().__init__
def PositionwiseFeedForward(
dim, dropout:float=0.0, act:str='reglu', mlp_ratio:int=1
):
A sequential container.
Modules will be added to it in the order they are passed in the constructor. Alternatively, an OrderedDict of modules can be passed in. The forward() method of [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) accepts any input and forwards it to the first module it contains. It then “chains” outputs to inputs sequentially for each subsequent module, finally returning the output of the last module.
The value a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) provides over manually calling a sequence of modules is that it allows treating the whole container as a single module, such that performing a transformation on the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) applies to each of the modules it stores (which are each a registered submodule of the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential)).
What’s the difference between a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) and a :class:torch.nn.ModuleList? A ModuleList is exactly what it sounds like–a list for storing Module s! On the other hand, the layers in a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) are connected in a cascading way.
Example::
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(
OrderedDict(
[
("conv1", nn.Conv2d(1, 20, 5)),
("relu1", nn.ReLU()),
("conv2", nn.Conv2d(20, 64, 5)),
("relu2", nn.ReLU()),
]
)
)t = torch.randn(2,3,10)
m = PositionwiseFeedForward(10, dropout=0., act='reglu', mlp_ratio=1)
test_eq(m(t).shape, t.shape)
m = PositionwiseFeedForward(10, dropout=0., act='smelu', mlp_ratio=1)
test_eq(m(t).shape, t.shape)
def ScaledDotProductAttention(
d_model, n_heads, attn_dropout:float=0.0, res_attention:bool=False, lsa:bool=False
):
Scaled Dot-Product Attention module (Attention is all you need by Vaswani et al., 2017) with optional residual attention from previous layer (Realformer: Transformer likes residual attention by He et al, 2020) and locality self sttention (Vision Transformer for Small-Size Datasets by Lee et al, 2021)
B = 16
C = 10
M = 1500 # seq_len
n_heads = 1
D = 128 # model dimension
N = 512 # max_seq_len - latent's index dimension
d_k = D // n_heads
xb = torch.randn(B, C, M)
xb = (xb - xb.mean()) / xb.std()
# Attention
# input (Q)
lin = nn.Linear(M, N, bias=False)
Q = lin(xb).transpose(1,2)
test_eq(Q.shape, (B, N, C))
# q
to_q = nn.Linear(C, D, bias=False)
q = to_q(Q)
q = nn.LayerNorm(D)(q)
# k, v
context = xb.transpose(1,2)
to_kv = nn.Linear(C, D * 2, bias=False)
k, v = to_kv(context).chunk(2, dim = -1)
k = k.transpose(-1, -2)
k = nn.LayerNorm(M)(k)
v = nn.LayerNorm(D)(v)
test_eq(q.shape, (B, N, D))
test_eq(k.shape, (B, D, M))
test_eq(v.shape, (B, M, D))
output, attn, scores = ScaledDotProductAttention(D, n_heads, res_attention=True)(q.unsqueeze(1), k.unsqueeze(1), v.unsqueeze(1))
test_eq(output.shape, (B, 1, N, D))
test_eq(attn.shape, (B, 1, N, M))
test_eq(scores.shape, (B, 1, N, M))
scores.mean(), scores.std()(tensor(-2.3159e-10, grad_fn=<MeanBackward0>),
tensor(0.9743, grad_fn=<StdBackward0>))
def MultiheadAttention(
d_model, n_heads, d_k:NoneType=None, d_v:NoneType=None, res_attention:bool=False, attn_dropout:float=0.0,
proj_dropout:float=0.0, qkv_bias:bool=True, lsa:bool=False
):
Same as nn.Module, but no need for subclasses to call super().__init__
q = torch.rand([16, 3, 50, 8])
k = torch.rand([16, 3, 50, 8]).transpose(-1, -2)
v = torch.rand([16, 3, 50, 6])
attn_mask = torch.triu(torch.ones(50, 50)) # shape: q_len x q_len
key_padding_mask = torch.zeros(16, 50)
key_padding_mask[[1, 3, 6, 15], -10:] = 1
key_padding_mask = key_padding_mask.bool()
print('attn_mask', attn_mask.shape, 'key_padding_mask', key_padding_mask.shape)
output, attn = ScaledDotProductAttention(24, 3, attn_dropout=.1)(q, k, v, attn_mask=attn_mask, key_padding_mask=key_padding_mask)
output.shape, attn.shapeattn_mask torch.Size([50, 50]) key_padding_mask torch.Size([16, 50])(torch.Size([16, 3, 50, 6]), torch.Size([16, 3, 50, 50]))t = torch.rand(16, 50, 128)
output, attn = MultiheadAttention(d_model=128, n_heads=3, d_k=8, d_v=6)(t, t, t, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
output.shape, attn.shape(torch.Size([16, 50, 128]), torch.Size([16, 3, 50, 50]))Test multi-head attention with self-locality attention
# lsa (locality self-sttention)
t = torch.rand(16, 50, 128)
attn_mask = torch.eye(50).reshape(1, 1, 50, 50).bool()
output, attn = MultiheadAttention(d_model=128, n_heads=8, lsa=True)(t, t, t, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
output.shape, attn.shape(torch.Size([16, 50, 128]), torch.Size([16, 8, 50, 50]))t = torch.rand(16, 50, 128)
att_mask = (torch.rand((50, 50)) > .85).float()
att_mask[att_mask == 1] = -np.inf
mha = MultiheadAttention(d_model=128, n_heads=3, d_k=8, d_v=6)
output, attn = mha(t, t, t, attn_mask=att_mask)
test_eq(torch.isnan(output).sum().item(), 0)
test_eq(torch.isnan(attn).sum().item(), 0)
loss = output[:2, :].sum()
test_eq(torch.isnan(loss).sum().item(), 0)
loss.backward()
for n, p in mha.named_parameters():
if p.grad is not None:
test_eq(torch.isnan(p.grad).sum().item(), 0)t = torch.rand(16, 50, 128)
attn_mask = (torch.rand((50, 50)) > .85)
# True values will be masked
mha = MultiheadAttention(d_model=128, n_heads=3, d_k=8, d_v=6)
output, attn = mha(t, t, t, attn_mask=att_mask)
test_eq(torch.isnan(output).sum().item(), 0)
test_eq(torch.isnan(attn).sum().item(), 0)
loss = output[:2, :].sum()
test_eq(torch.isnan(loss).sum().item(), 0)
loss.backward()
for n, p in mha.named_parameters():
if p.grad is not None:
test_eq(torch.isnan(p.grad).sum().item(), 0)
def MultiConv1d(
ni, nf:NoneType=None, kss:list=[1, 3, 5, 7], keep_original:bool=False, separable:bool=False, dim:int=1,
kwargs:VAR_KEYWORD
):
Module that applies multiple convolutions with different kernel sizes
t = torch.rand(16, 6, 37)
test_eq(MultiConv1d(6, None, kss=[1,3,5], keep_original=True)(t).shape, [16, 24, 37])
test_eq(MultiConv1d(6, 36, kss=[1,3,5], keep_original=False)(t).shape, [16, 36, 37])
test_eq(MultiConv1d(6, None, kss=[1,3,5], keep_original=True, dim=-1)(t).shape, [16, 6, 37*4])
test_eq(MultiConv1d(6, 60, kss=[1,3,5], keep_original=True)(t).shape, [16, 60, 37])
test_eq(MultiConv1d(6, 60, kss=[1,3,5], separable=True)(t).shape, [16, 60, 37])
def LSTMOutput(
):
Same as nn.Module, but no need for subclasses to call super().__init__
t = ([1], [2], [3])
test_eq(LSTMOutput()(t), [1])
def emb_sz_rule(
n_cat
):
Rule of thumb to pick embedding size corresponding to n_cat (original from fastai)
test_eq(emb_sz_rule(7), 5)
def TSEmbedding(
ni, nf, std:float=0.01, padding_idx:NoneType=None
):
Embedding layer with truncated normal initialization adapted from fastai
def MultiEmbedding(
c_in, n_cat_embeds, cat_embed_dims:NoneType=None, cat_pos:NoneType=None, std:float=0.01,
cat_padding_idxs:NoneType=None
):
Same as nn.Module, but no need for subclasses to call super().__init__
a = alphabet[np.random.randint(0,3,40)]
b = ALPHABET[np.random.randint(6,10,40)]
c = np.random.rand(40).reshape(4,1,10)
map_a = {k:v for v,k in enumerate(np.unique(a))}
map_b = {k:v for v,k in enumerate(np.unique(b))}
n_embeds = [len(m.keys()) for m in [map_a, map_b]]
szs = [emb_sz_rule(n) for n in n_embeds]
a = np.asarray(a.map(map_a)).reshape(4,1,10)
b = np.asarray(b.map(map_b)).reshape(4,1,10)
inp = torch.from_numpy(np.concatenate((c,a,b), 1)).float()
memb = MultiEmbedding(3, n_embeds, cat_pos=[1,2])
# registered buffers are part of the state_dict() but not module.parameters()
assert all([(k in memb.state_dict().keys()) for k in ['cat_pos', 'cont_pos']])
embeddings = memb(inp)
print(n_embeds, szs, inp.shape, embeddings.shape)
test_eq(embeddings.shape, (inp.shape[0],sum(szs)+1,inp.shape[-1]))[3, 4] [3, 3] torch.Size([4, 3, 10]) torch.Size([4, 7, 10])me = MultiEmbedding(3, 4, cat_pos=2)
test_eq(me.cat_embed[0].weight.shape, (4,3))
test_eq(me.cat_pos.cpu().item(), 2)