from tsai.data.basics import *
from tsai.learner import *XCMPlus
This is an unofficial PyTorch implementation of XCM created by Ignacio Oguiza (oguiza@timeseriesAI.co).
XCMPlus
def XCMPlus(
c_in:int, c_out:int, seq_len:Optional=None, nf:int=128, window_perc:float=1.0, flatten:bool=False,
custom_head:callable=None, concat_pool:bool=False, fc_dropout:float=0.0, bn:bool=False, y_range:tuple=None,
kwargs:VAR_KEYWORD
):
A sequential container.
Modules will be added to it in the order they are passed in the constructor. Alternatively, an OrderedDict of modules can be passed in. The forward() method of [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) accepts any input and forwards it to the first module it contains. It then “chains” outputs to inputs sequentially for each subsequent module, finally returning the output of the last module.
The value a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) provides over manually calling a sequence of modules is that it allows treating the whole container as a single module, such that performing a transformation on the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) applies to each of the modules it stores (which are each a registered submodule of the [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential)).
What’s the difference between a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) and a :class:torch.nn.ModuleList? A ModuleList is exactly what it sounds like–a list for storing Module s! On the other hand, the layers in a [Sequential](https://timeseriesAI.github.io/tsai/models.tabfusiontransformer.html#sequential) are connected in a cascading way.
Example::
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1, 20, 5), nn.ReLU(), nn.Conv2d(20, 64, 5), nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(
OrderedDict(
[
("conv1", nn.Conv2d(1, 20, 5)),
("relu1", nn.ReLU()),
("conv2", nn.Conv2d(20, 64, 5)),
("relu2", nn.ReLU()),
]
)
)dsid = 'NATOPS'
X, y, splits = get_UCR_data(dsid, split_data=False)
tfms = [None, TSCategorize()]
dls = get_ts_dls(X, y, splits=splits, tfms=tfms)
model = XCMPlus(dls.vars, dls.c, dls.len)
learn = ts_learner(dls, model, metrics=accuracy)
xb, yb = dls.one_batch()
bs, c_in, seq_len = xb.shape
c_out = len(np.unique(yb.cpu().numpy()))
model = XCMPlus(c_in, c_out, seq_len, fc_dropout=.5)
test_eq(model.to(xb.device)(xb).shape, (bs, c_out))
model = XCMPlus(c_in, c_out, seq_len, concat_pool=True)
test_eq(model.to(xb.device)(xb).shape, (bs, c_out))
model = XCMPlus(c_in, c_out, seq_len)
test_eq(model.to(xb.device)(xb).shape, (bs, c_out))
modelXCMPlus(
(backbone): _XCMPlus_Backbone(
(conv2dblock): Sequential(
(0): Unsqueeze(dim=1)
(1): Conv2dSame(
(conv2d_same): Conv2d(1, 128, kernel_size=(1, 51), stride=(1, 1))
)
(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
)
(conv2d1x1block): Sequential(
(0): Conv2d(128, 1, kernel_size=(1, 1), stride=(1, 1))
(1): ReLU()
(2): Squeeze(dim=1)
)
(conv1dblock): Sequential(
(0): Conv1d(24, 128, kernel_size=(51,), stride=(1,), padding=(25,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
(conv1d1x1block): Sequential(
(0): Conv1d(128, 1, kernel_size=(1,), stride=(1,))
(1): ReLU()
)
(concat): Concat(dim=1)
(conv1d): Sequential(
(0): Conv1d(25, 128, kernel_size=(51,), stride=(1,), padding=(25,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
)
)
(head): Sequential(
(0): GAP1d(
(gap): AdaptiveAvgPool1d(output_size=1)
(flatten): Reshape(bs)
)
(1): LinBnDrop(
(0): Linear(in_features=128, out_features=6, bias=True)
)
)
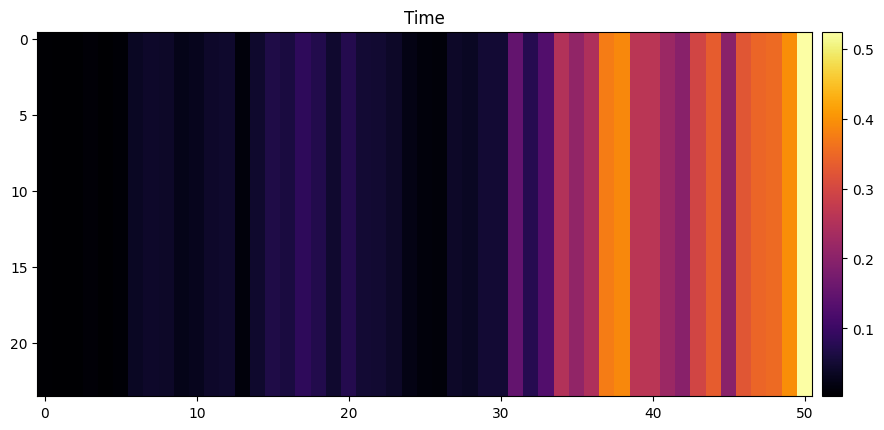
)model.show_gradcam(xb, yb)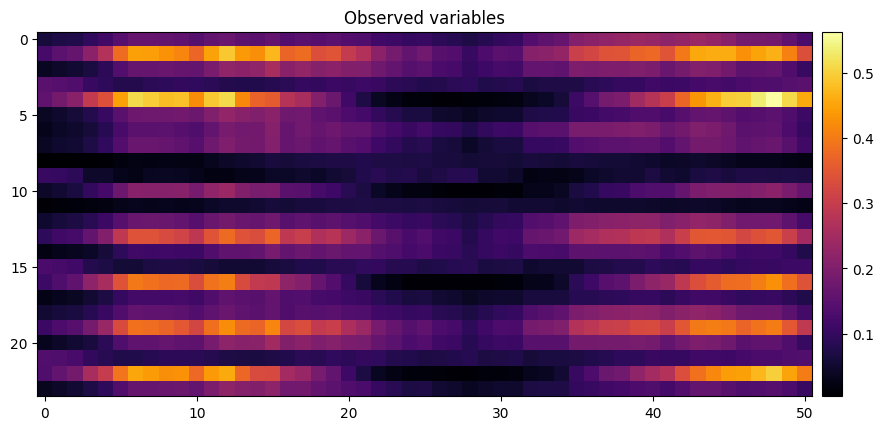
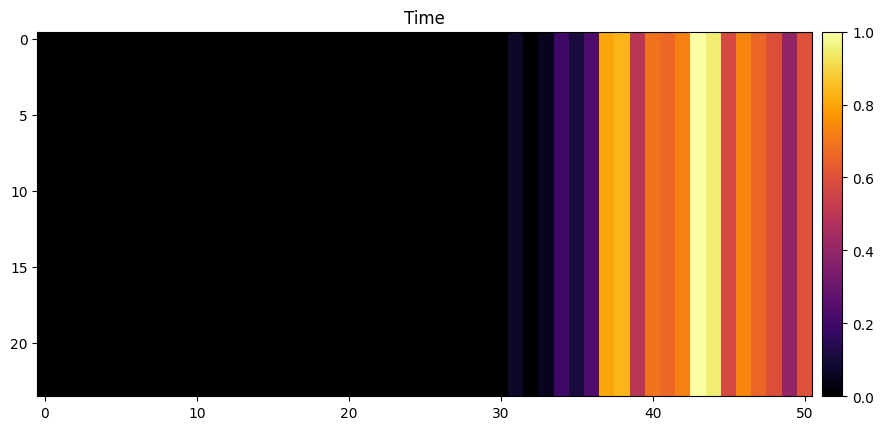
model.show_gradcam(xb[0], yb[0])[W NNPACK.cpp:53] Could not initialize NNPACK! Reason: Unsupported hardware.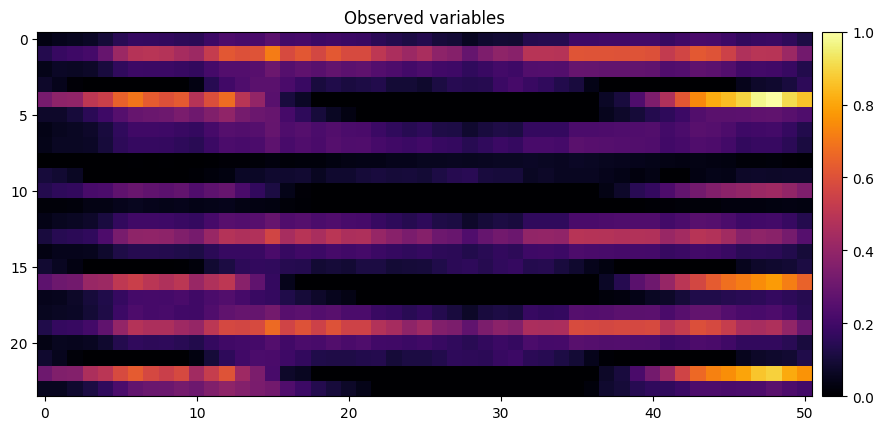
bs = 16
n_vars = 3
seq_len = 12
c_out = 1
xb = torch.rand(bs, n_vars, seq_len)
new_head = partial(conv_lin_nd_head, d=(5, 2))
net = XCMPlus(n_vars, c_out, seq_len, custom_head=new_head)
print(net.to(xb.device)(xb).shape)
net.headtorch.Size([16, 5, 2])create_conv_lin_nd_head(
(0): Conv1d(128, 1, kernel_size=(1,), stride=(1,))
(1): Linear(in_features=12, out_features=10, bias=True)
(2): Transpose(-1, -2)
(3): Reshape(bs, 5, 2)
)bs = 16
n_vars = 3
seq_len = 12
c_out = 2
xb = torch.rand(bs, n_vars, seq_len)
net = XCMPlus(n_vars, c_out, seq_len)
change_model_head(net, create_pool_plus_head, concat_pool=False)
print(net.to(xb.device)(xb).shape)
net.headtorch.Size([16, 2])Sequential(
(0): AdaptiveAvgPool1d(output_size=1)
(1): Reshape(bs)
(2): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): Linear(in_features=128, out_features=512, bias=False)
(4): ReLU(inplace=True)
(5): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(6): Linear(in_features=512, out_features=2, bias=False)
)